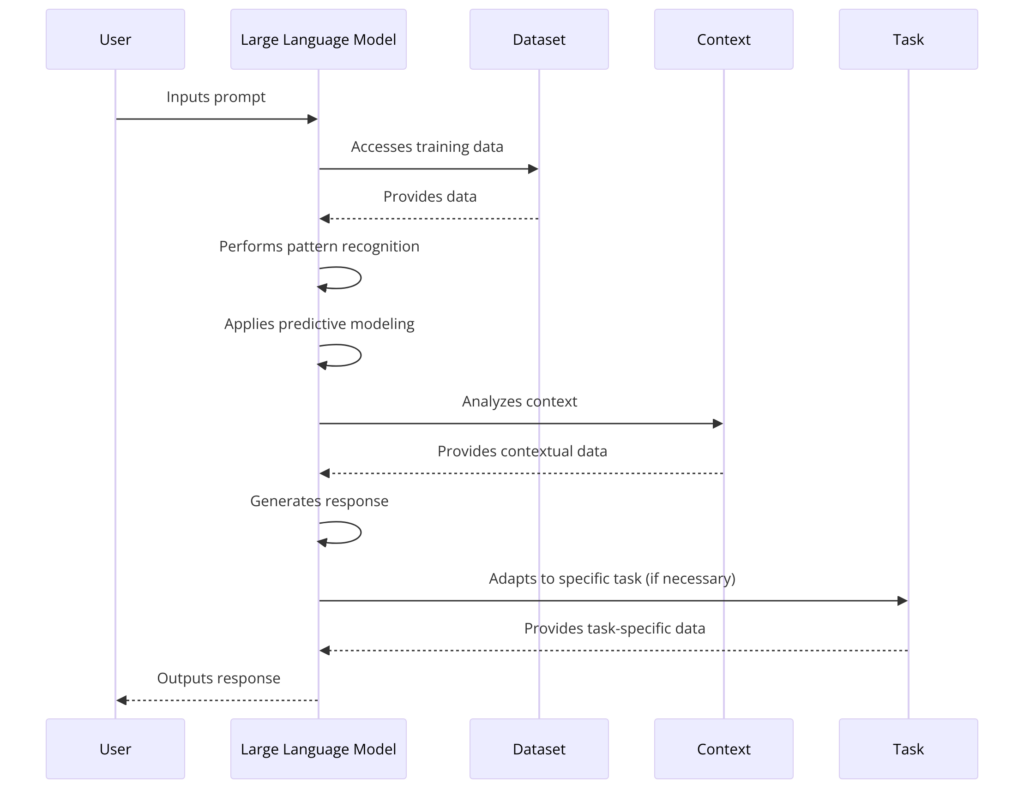
Large Language Models (LLMs) are powerful tools that leverage pattern recognition, predictive modeling, contextual awareness, and fine-tuning to generate human-like text. While they do not possess true understanding or continuous learning, their ability to process and generate text at scale makes them indispensable across multiple fields.
| Model Name | Developer | Open-Source or Closed-Source | Latest Version (as of 2025) |
|---|---|---|---|
| GPT-4o | OpenAI | Closed-source | GPT-4o |
| Gemini 1.5 | Google DeepMind | Closed-source | Gemini 1.5 |
| DeepSeek LLM | DeepSeek | Open-source | DeepSeek LLM |
| Llama 3 | Meta | Open-source | Llama 3 |
| Qwen-2 | Alibaba | Open-source | Qwen-2 |
| Grok3 | xAI | Closed-source | Grok3 |
How Large Language Models (LLMs) Work: Key Principles
Large Language Models (LLMs) like GPT-4o (closed-source by OpenAI), Gemini 1.5 (closed-source by Google DeepMind), DeepSeek LLM (open-source by DeepSeek), Llama 3 (open-source by Meta), and Qwen-2 (open-source by Alibaba) operate by recognizing patterns, making predictions, and generating responses based on four key principles:
1. Pattern Recognition
LLMs learn from vast amounts of text data, detecting statistical patterns in words, phrases, and sentence structures. This allows them to map relationships between concepts and predict likely language sequences. However, they do not “understand” language like humans do—they generate responses based on learned probabilities.
2. Predictive Modeling
At their core, LLMs function by predicting the most probable next token (word or subword) in a sequence. This statistical approach enables them to generate fluid, grammatically correct, and contextually relevant text, mimicking natural language patterns.
3. Context Awareness
Modern LLMs use transformer architectures with attention mechanisms (such as the self-attention mechanism in the Transformer model) to assess which parts of an input matter most. This helps them maintain coherence across longer passages and generate responses that align with user intent. However, their “understanding” is still based on probabilities, not reasoning.
4. Adaptability Through Fine-Tuning
LLMs are initially trained on large datasets and do not autonomously “learn” after deployment. However, they can be fine-tuned with domain-specific data to improve accuracy for specialized tasks, such as medical diagnosis, legal analysis, or customer service. Additionally, techniques like Retrieval-Augmented Generation (RAG) allow them to pull in up-to-date information without needing full retraining.
| Principle | Description |
|---|---|
| Pattern Recognition | LLMs learn from vast datasets by identifying statistical patterns in text, allowing them to recognize linguistic structures. |
| Predictive Modeling | They predict the next token (word or subword) in a sequence based on probabilities, ensuring fluent and coherent text generation. |
| Context Awareness | Using transformer architectures and attention mechanisms, LLMs assess which parts of an input are most relevant, improving contextual coherence. |
| Adaptability & Fine-Tuning | LLMs do not learn autonomously but can be fine-tuned for specific applications. Techniques like Retrieval-Augmented Generation (RAG) allow them to integrate real-time data. |
How LLMs Work: Key Principles
The Power & Limitations of LLMs
These principles allow LLMs to generate grammatically correct and contextually relevant language. The above principles enable LLMs to process, generate and adapt creating language that is not only grammatically correct but also contextually and semantically meaningful. Their adaptability makes them useful for a wide range of applications, from content creation to coding assistance. However, they have limitations, such as:
- Lack of true reasoning – They do not “think” or “understand” but generate responses based on probability.
- Fixed knowledge after training – Unless fine-tuned or integrated with external data sources (e.g., retrieval-augmented methods), they cannot update knowledge in real time.
- Potential biases – Since LLMs learn from vast internet datasets, they can sometimes reflect biases present in their training data.
| Capabilities | Limitations |
|---|---|
| Generate human-like text | No real understanding – LLMs generate responses based on probabilities, not reasoning. |
| Adaptable for various domains | Fixed knowledge post-training – Unless fine-tuned or integrated with real-time retrieval, their knowledge is static. |
| Process vast amounts of text | Can reflect biases from training data, requiring careful filtering. |